
Our first research project: Locating QA perspectives
Question answer systems promise to be “all-knowing” – encompassing “all” knowledge and understanding knowing what information you are searching for.
As Google’s VP of Engineering wrote in 2012, now “Google understands the difference… between Taj Mahal the monument (and) Taj Mahal the musician”.
But all knowledge is situated. As Donna Harraway famously wrote, all knowledges (even scientific knowledges) are partial.
All knowledges offer a view “from somewhere” rather than the “nowhere” that is often promised. The most objective knowledges are those that acknowledge their partiality.
Our first project evaluated current question answering systems in the light of these promises and contingencies.
Rather than simply a source, QA systems act as communicative partners in dialogue with us. Where were these actants “coming from”? From which perspective? How well did they represent Australian individuals far from their origins in the United States?
Our Research Examined How QA Systems Respond to Questions about people
We took the names of 34 recent recipients of the 2021 Australian honours awards – 17 women and 17 men – and asked Alexa, Google Assistant and Siri in both speaker and mobile versions to tell us who they were.
These individuals are noteworthy Australians who had all been represented in the news media and the web more generally.
We then quantitatively and qualitatively analysed the results according to the three heuristics below.

#1 Ignorance and uncertainty
QA systems use automated means to connect entities in vast knowledge graphs using data from the web.
There will always be moments when they don’t know the answer to a user’s question and/or when they provide an answer for which statistical certainty is low.
Uncertainty is a key feature of all statistical and machine learning systems. We would expect trustworthy communicative partners to indicate when they are ignorant (don’t know) and when they are uncertain of the results (if results are based on volatile, trending or conflicting information, for example).
#2 Sources
Understanding what the source is is critical for a user’s ability to evaluate a claim provided by a QA system. “Who is behind the information?” and “What is the evidence?” are two of the core competences of civic online reasoning.
A trustworthy QA system, then, would provide not only the source of its claims but would provide the source in a way that would enable the user to look it up to check whether it has been accurately represented.
“Wikipedia”, for example, would be an inadequate source by this measure. “English Wikipedia” and the inclusion of the specific version/URL from which the information was derived would be.
#3 Biases
As indicated above, all knowledge is partial. All knowledge comes from “somewhere”. The web is generally biased towards certain knowledges, but sources that derive their information from the web will make selections and prioritise particular sources that they deem credible and/or accessible according to their own parameters.
We expect a trustworthy QA system to make visible its biases or at least for independent parties to be able to determine the biases of knowledge sources (as we see in the traditional newspaper and broadcasting arena).
Portraits of QA Systems
Based on how they answered our questions, we developed portraits of each digital assistant according to these heuristics
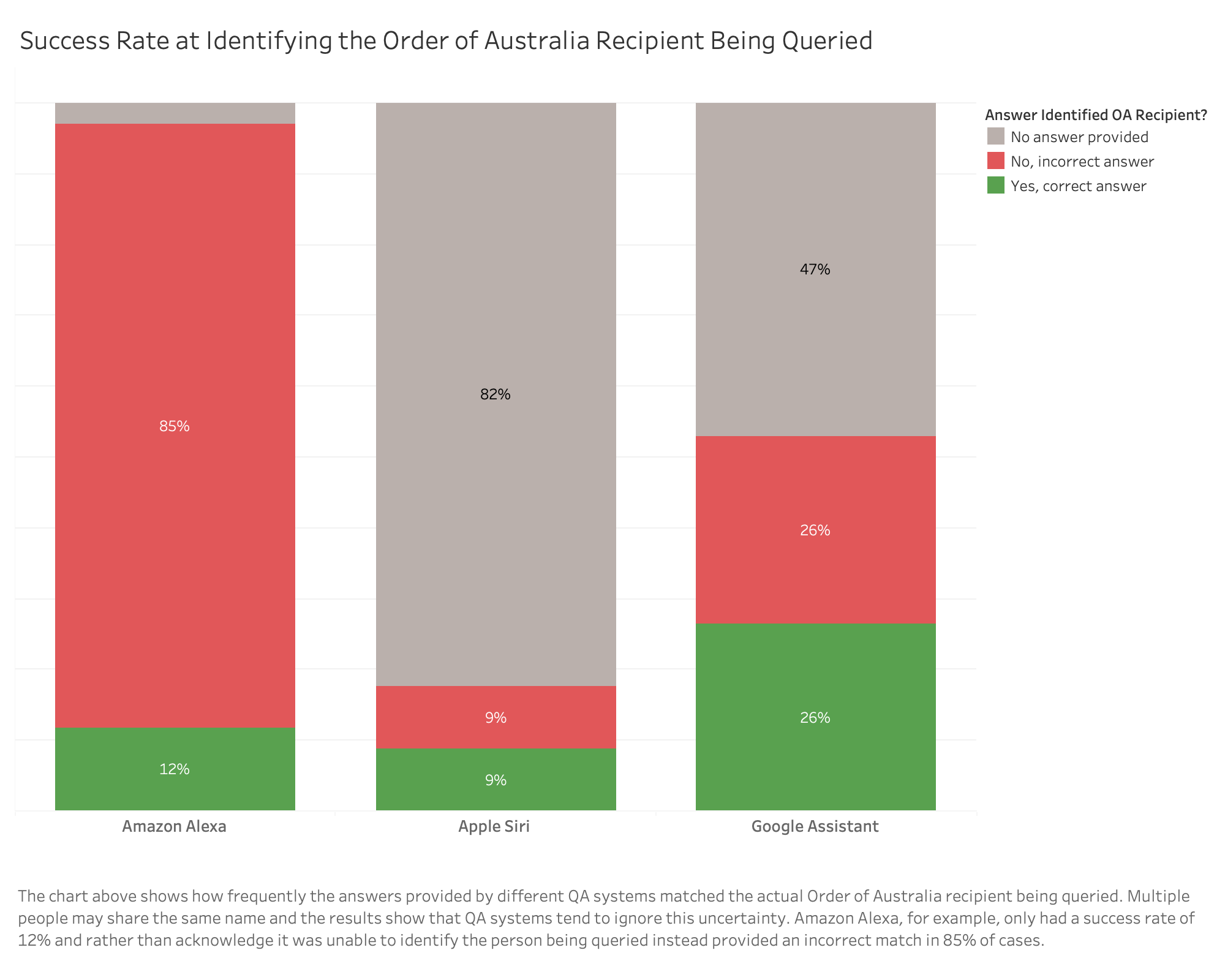
Ignorance and uncertainty: Alexa was least likely to acknowledge its ignorance and uncertainty. It never acknowledged uncertainty even though it provided incorrect results in most (69%) cases and only acknowledged that it did not have an answer in 6% of cases.
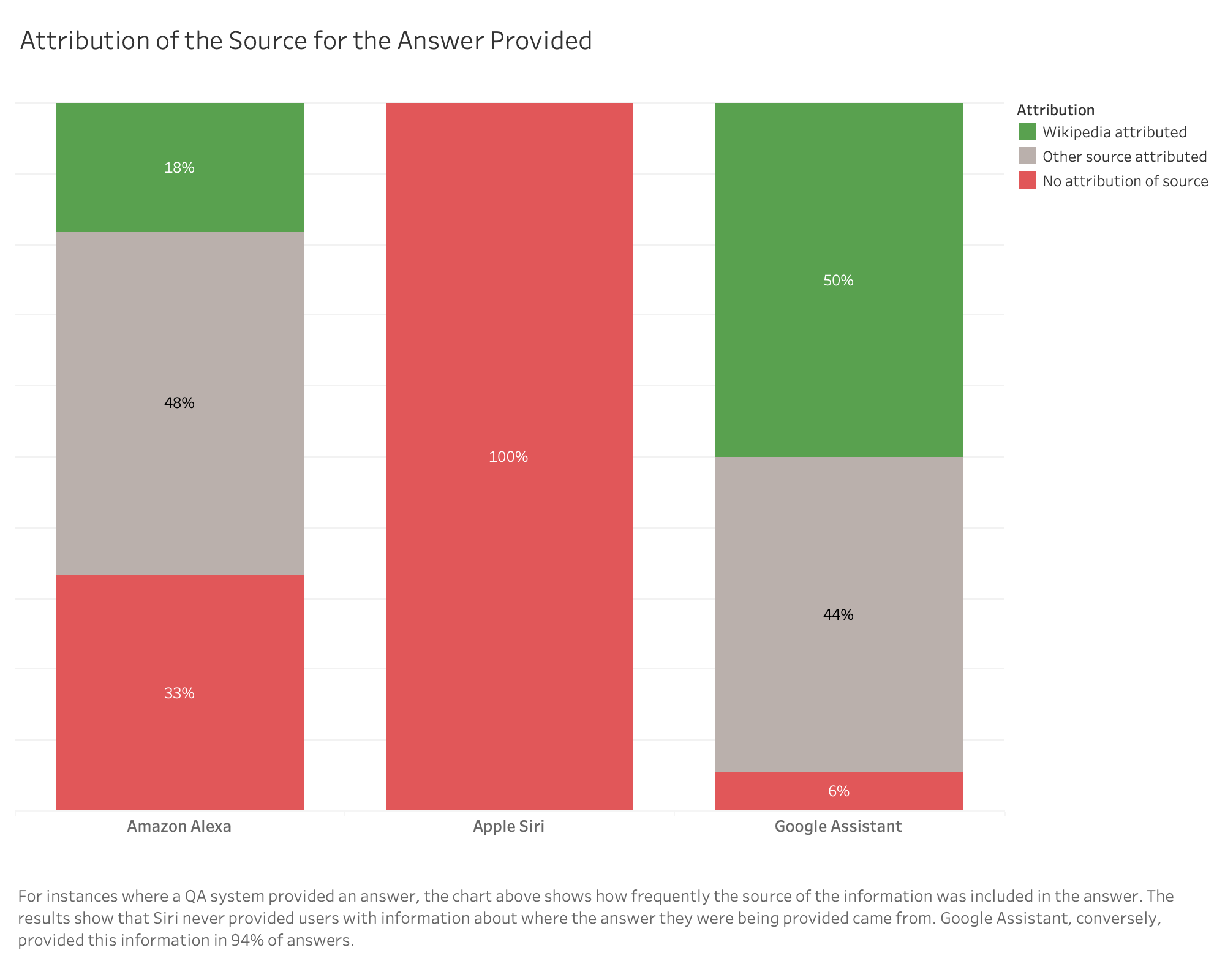
Sources: Alexa acknowledged its sources in only a third of its results. Of those third, a third were acknowledged as coming from Wikipedia.
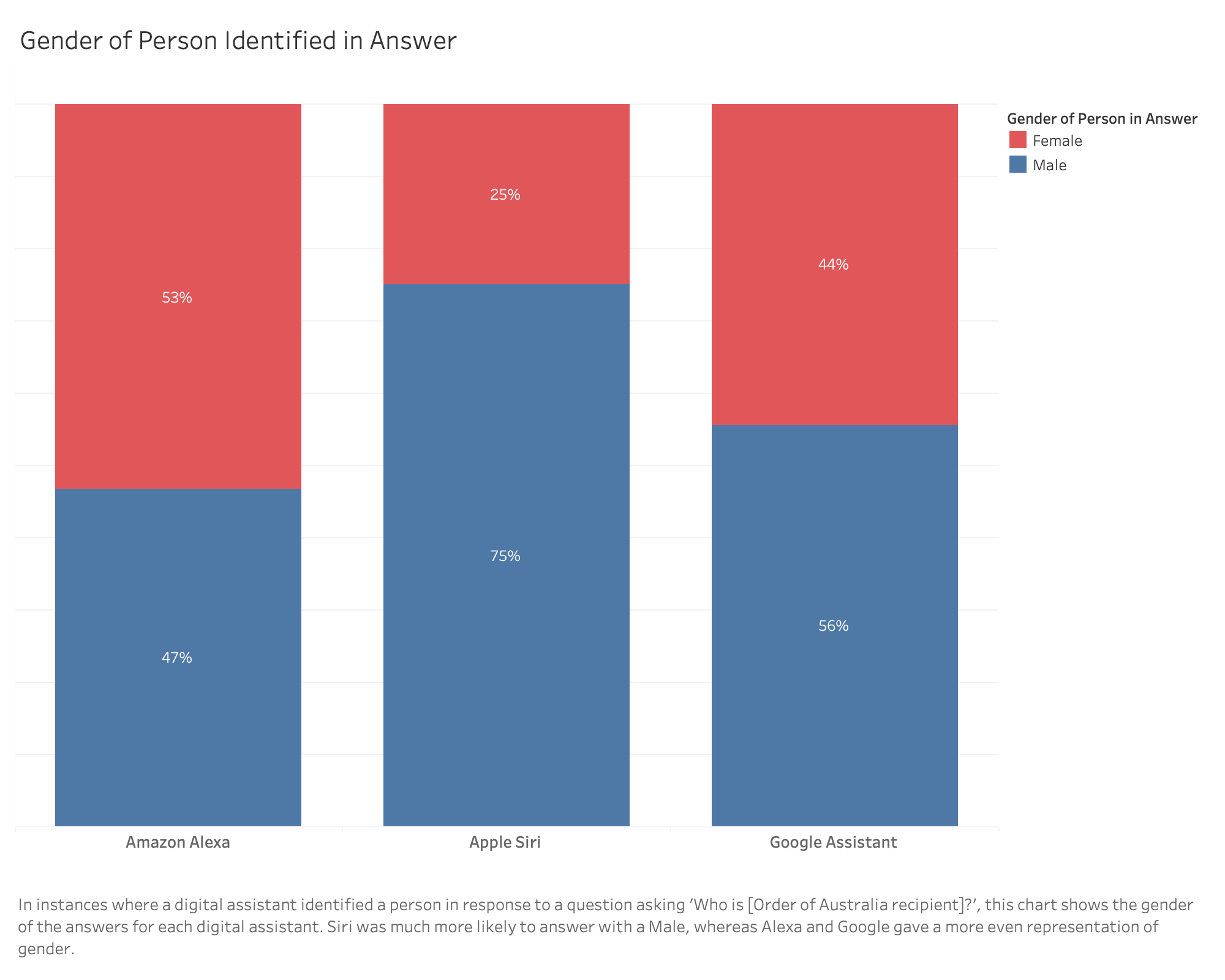
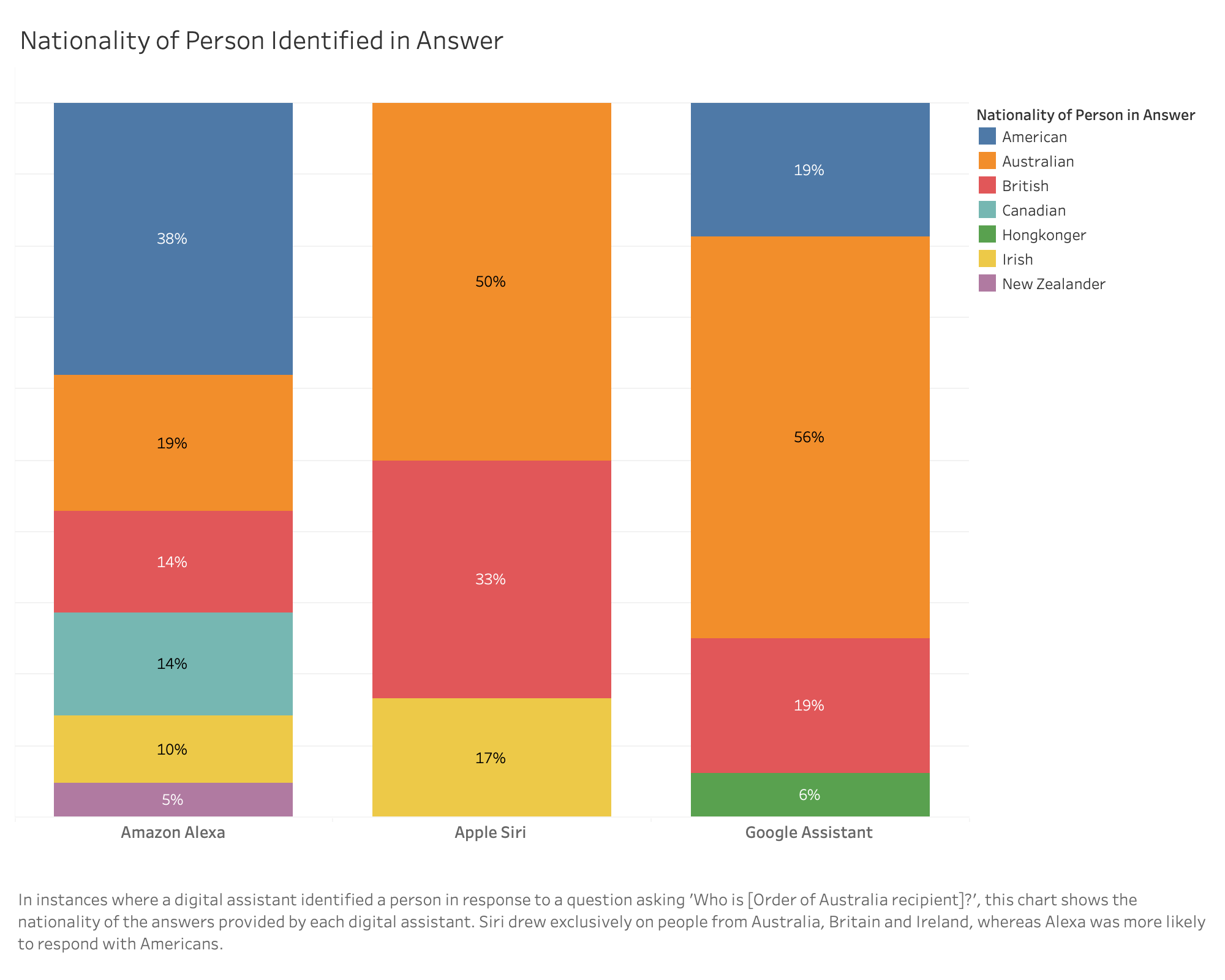
Biases: Alexa had a strong bias towards providing an answer with an American who had the same name (in 62% of cases) without asking for clarification. Alexa was the most biased towards Americans of the three question answering systems in the study.

Apple Siri
Ignorance and uncertainty: Siri provided no answer in 78% of the cases but acknowledged its ignorance in only 4% cases with the words: “Sorry I can’t get that info for you here”. In some cases, Siri acknowledged its uncertainty with the words: “This might answer your question” but there was no consistency or detail provided about the level or source of uncertainty.
Sources: Siri consistently provided a list of external links where it was able to identify the subject. But Siri didn’t generally attribute its answers in a way that clearly communicated the external link as the source of the material. Wikipedia was consistently provided as one of the external links and Wolfram Alpha seemed to be the source in two cases.
Biases: Siri was most likely to respond to requests about Australian individuals in our sample with details of a person from either Britain (67%) or Ireland (17%).

Google Assistant
Ignorances and uncertainties: Google Assistant was most likely to acknowledge when it “didn’t know” the answer with the words: “Sorry I don’t have information about that” but only in about half of the cases where it didn’t have an answer.
Sources: Google Assistant was the service most likely to identify the source of the information its answer was based on (in 94% of cases). Wikipedia was cited in almost half of the answers provided (42% of cases).
Biases: Google Assistant had a strong bias towards answering our queries about Australian individuals with Americans with the same name (in 47% of cases).
Implications of our research
All three QA systems rely on web data. They are accessed via devices that collect location information about users, purportedly for personalisation. The questions asked were exactly the kind of questions that QA systems should excel at: they are about particular entities (people), about which there is no dispute (factual information about those people). However, all three presented answers that suggested knowledge holes (where there is no knowledge about the entity), identified the wrong person (particularly US and UK entities), or in at least one case, identified a fictional entity.
The QAs did not seek clarification, use contextual cues (such as IP addresses), or weight by relevance. Instead, they weighted by how common the key entity name is on a US-centric web. Some were more likely to identify Americans rather than British people, but all were unlikely to recognise Australians. None were able to disambiguate between individuals with the same name, despite the promises that knowledge graph products would be able to achieve this. And both Alexa and Siri had problems in meaningfully attributing the source of their answers.

What's next?
Question answering services are features of digital assistants that promise to assist us with knowledge seeking. But do they assist us or deny our agency? Question answering machines represent the knowledge of others in a way that can position them as unquestionable oracles. This reduces our agency to critically assess knowledge. This doesn’t have to be so. QA machines can reflect knowledge that aids our critical features for example by reflecting when they are ignorant or uncertain as well as revealing their sources. We need to continue to evaluate these novel knowledge machines according to whether they act as trustworthy communicative companions, rather than whether they are simply “accurate” or not by some “global” standard. All knowledge is situated. So too the question answering machines whose authority continues to grow.